State モナドの代わりに Reader モナドを使う
2020年01月31日に投稿 (2020年03月29日に更新) • カテゴリ:プログラミング
- 注意
- この記事は公開当時主張に誤りを含んでいたため,大幅に書き直しています.また,公開当時の主張の誤りについても,付録として載せておきました.
Haskell で State モナドはモナドの代表格だ.Haskell 入門者は,多くの場合,状態を伴った計算を State モナドで書くことを習うだろう.しかし,実用上の多くの場面では,State モナドではなく他の選択肢を選んだ方がいい場合がある.一つの選択肢が,Reader モナドと可変参照を使う方法だ.今回は,この手法を使う利点と利用場面について考えていこうと思う.
なお,環境として以下を想定している.
| GHC のバージョン | 8.6.5 |
| Cabal のバージョン | 3.0.0.0 |
IORef の神話
Haskell はかなり多くの神話を持つ言語だ.その中の一つに,以下のものがある.
IORef を使うとパフォーマンスは良いが純粋性を損なう.なので,パフォーマンスを気にしないなら State モナドを使うべきだ.
巷の多くの例では,この言葉は都市伝説に過ぎない.まずは,その辺について見ておこう.これは,IORef などの可変参照と State モナドの違いを理解する上でも役に立つはずだし,本記事の良い導入となるだろう.
さて,以下のサンプルコードを見てみる:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import Control.Monad.State.Strict import Data.IORef sumByState :: [Int] -> Int sumByState l = execState (go l) 0 where go [] = pure () go (x:xs) = do modify' \s -> s + x go xs sumByIORef :: [Int] -> IO Int sumByIORef l = do r <- newIORef 0 go r l readIORef r where go _ [] = pure () go r (x:xs) = do modifyIORef' r \s -> s + x go r xs |
この場合,sumByState と sumByIORef でどちらがどれくらい良いパフォーマンスを期待できるだろうか? まずは,実測してみよう.criterion を使って,ベンチマークコードを書いてみる:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | module Main where import qualified Criterion.Main as Criterion main :: IO () main = Criterion.defaultMain [ bgroup "sumByState" $ Criterion.nf sumByState , bgroup "sumByIORef" \xs -> Criterion.nfIO $ sumByIORef xs ] where bgroup n f = Criterion.bgroup n $ benches f benches f = [ Criterion.bench ("n=" ++ show n) $ f xs | (n, xs) <- samples ] samples = do i <- [1..5] let n = 10 ^ i pure (n, [1..n]) |
このコードによる測定結果を,グラフにプロットしてみると以下のようになる:
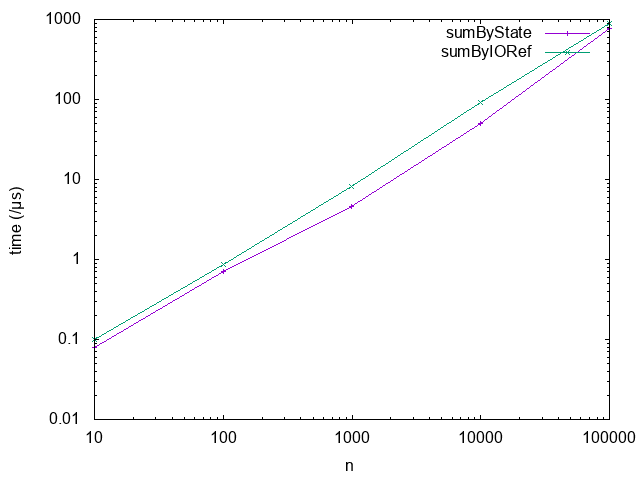
どちらの軸も対数でとってることに注意.見ての通り,常に sumByState の方が sumByIORef より速い.この場合,State モナドは,IORef を使う場合に比べ,「パフォーマンスが良くて,しかも純粋性を損なわない」わけだ.さて,なぜこのような結果になるのだろう? Haskell は純粋性を持つコードを贔屓しているのだろうか? それとも State モナドの実装は,裏で高度な技術が使われていて,それによって高効率な動作をするようになっているのだろうか?
実は,State モナドと IORef のコードは,やってることはそう違いはない.これは,大局的に見てという話ではなく,本当にそれぞれの操作が割と対応したコードになっているのだ.にも関わらず違いが出るのは何故なのだろう? このカラクリを紐解いていこう.GHC では通常最適化レベル 1 でコンパイルをするわけだが,まずは他のレベルでどうなるか見てみよう.cabal を使っている場合は,
cabal build --enable-optimization=n && cabal --enable-optimization=n exec ...
というようにすれば,試せる.結果は,大体以下のような結果になる:
- 最適化レベル2
- sumByIORef の方はあまり変わらないが,sumByState はさらに性能が良くなり,両者の性能差が浮き彫りになる.
- 最適化レベル0
- sumByIORef の方が sumByState に比べ2倍ほど速くなる.
最適化レベル0の結果から分かる通り,実は State モナドと IORef の性能差は,最適化によって生まれる.最適化レベル1において, sumByState / sumByIORef はそれぞれ概ね次のようなコードに最適化される:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | {-# LANGUAGE MagicHash #-} {-# LANGUAGE UnboxedTuples #-} import GHC.Base import GHC.Prim sumByState :: [Int] -> Int sumByState l = case go l 0 of (# _, r #) -> r where go :: [Int] -> Int -> (# (), Int #) go xs acc = case xs of [] -> (# (), acc #) y:ys -> go ys (acc + y) sumByIORef :: [Int] -> IO Int sumByIORef l = IO \s0 -> case newMutVar# 0 s0 of { (# s1, r# #) -> case go (coerce (STRef r#)) l s1 of { (# s2, _ #) -> readMutVar# r s2 } } where go :: IORef Int -> [Int] -> State# RealWorld -> (# State# RealWorld, () #) go r xs s0 = case xs of [] -> (# s0, () #) y:ys -> case coerce r of r'@(STRef r#) -> case readMutVar# r# s0 of { (# s1, acc #) -> case writeMutVar# r# (acc + y) of { s2 -> go (coerce r') ys s2 } } |
幾人かは,このコードがまだ最適化の余地を残していることに気づくだろう.実際,最適化レベル2では,さらに w/w という最適化が入り,どちらも余計な処理が省かれる.特に, sumByState はその省かれた処理によって,かなり高速化される.ところでパッと見で, sumByState より sumByIORef の最適化コードは複雑に見える.多くの場合,ミクロな視点で見れば,コードは複雑なものより単純なものの方が速い.実際今回は, sumByState が sumByIORef の方が優っていた.ところが,この2つのコード,実際にやっていることにそう違いはない.IORef は,通常あるヒープ領域を指すポインタとして実装される.そして,そのヒープ領域には,実データのクロージャを指すポインタがやっぱり入っている.そこで,両者の違いは,
- 実データのクロージャを指すポインタを直接参照するか,一旦実データを指すポインタを参照しさらにそこから実データを参照する2段階の参照か
- Haskell の単純な構文を保っているか,readMutVar# / writeMutVar# などのプリミティブな命令が露出しているか
になる.ただ,2段階の参照になっても他の処理と比べて相対的にそこまで遅くなるというわけではなく,プリミティブな命令もコード生成時には単純にメモリ参照の命令に置き換わり,特別なランタイム API の呼び出しなどは通常起きない.なので,これらの違いは直接的にはパフォーマンスの違いに影響を及ばさないのだが,間接的には大きな影響を与える.一般に,GHC で IORef が通常の State モナドよりパフォーマンスで劣る点は以下のものだ:
- プリミティブな命令をコード生成まで展開できず,そこまでの最適化が阻害される.
- writeMutVar# は重い処理であり,単純に参照を取り換えるだけでなく,GC への特別な処理を要求する [1] .
1つ目の問題は,最適化レベル1ではそこまで現れていないが,最適化レベル2で sumByIORef が sumByState に性能差を広げられたことの主な要因になる.w/w 変換で, sumByState は次のように最適化できる:
1 2 3 4 5 6 7 8 9 | sumByState :: [Int] -> Int sumByState l = case go l 0# of (# _, r #) -> r where go :: [Int] -> Int# -> (# (), Int #) go xs acc# = case xs of [] -> (# (), I# acc# #) y:ys -> case y of I# y# -> go ys (acc# +# y#) |
本来の + では, I# を取って +# で計算した結果をまた I# で包むといったことをしてたのが,こうするとその処理が省ける他, Int# の値をいちいちヒープに入れなくて良くなり,かなり速度の改善が見込める.実際,速度はかなり改善する.IORef の方も似たようなことをやってるので,このような最適化を適用しようと思えばできるのだが,残念ながら適用されない.なぜなら,プリミティブ命令は実行コード生成時まで展開されず,最適化の適用にはプリミティブ命令の展開が必要だが,最適化は実行コード生成前に行われるため,結果的にミスマッチにより最適化が適用されないということが起こるからだ.つまり,最適化レベル2での sumByState と sumByIORef の対決は,片方は I# によるラップ処理を省きスタックへの参照のみで完結,もう片方は I# のラップ処理が必要で一々ヒープに書き込む操作も必要といったプログラム同士の悲惨な対決となってしまう.
2つ目の問題は,知るところでは知られた問題だ.一般に writeIORef は幾つかの側面から多用はやめた方がいいと言う通説がある.これは,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | sumByState :: Int -> Int sumByState n = evalState (go (10 * n) 0) 0 where go 0 !y = pure y go m !y = do s <- get when (m `mod` n == 0) do put $! s + 1 go (m - 1) (y + s) sumByIORef :: Int -> IO Int sumByIORef n = do r <- newIORef 0 go r (10 * n) 0 where go _ 0 !y = pure y go r m !y = do s <- readIORef r when (m `mod` n == 0) do writeIORef r $! s + 1 go r (m - 1) (y + s) |
のように, writeIORef を抑えたプログラムで速度を実測してみると分かるが,この場合当初は 40% ほどの性能差だったのが 10% ほどになる.つまり,最適化レベル1 での性能悪化の主な要因は,大雑把に言えば writeIORef の多用にあると言うことだ.
これまでの議論 [2] から,IORef が State モナドよりパフォーマンスの悪化を招きやすい,少なくとも State モナドより速くなることはないというのが,大方の結論になる.よって,GHC では,IORef より State モナドを使う方が,純粋な計算で完結でき,しかも速いのだ.これが,最初の話題が神話である所以だ.
IORef 再考
という話で終わると,単なる注意喚起になってしまうのだが,本題はここからだ.さて,IORef の問題点は以下の2点だった.
- プリミティブな命令をコード生成まで展開できず,そこまでの最適化が阻害される.
- writeMutVar# は重い処理であり,あまり多用してはいけない.
これは,別の言い方をすれば,
- プリミティブ命令を展開するような最適化が,そこまでパフォーマンスに大きく影響しない
- writeMutVar# をそこまで多用しない
コードであれば,IORef は有効ということになるのではないだろうか? 1つ目の用件は,スタック領域だけで完結しないような状態,つまり Int のようなものでなく Bool のような本質的に boxed なデータを扱うコードであれば,大体クリアできる. writeMutVar# についても,頻繁に変更しないが,参照は頻繁に行うような要件はいくらでもあるだろう.特に,今回対象にしたいのが,グローバルコンテキストだ.グローバルコンテキストの賛否はともかくとして,現実の多くのプログラムは,巨大で常駐し続けるプログラムの設定を管理するデータを持っている.通常グローバルコンテキストは,幾つかのフィールドから構成されていて,ネストされていたりもする.フィールドの中身はヒープに確保しなければいけないため,1つ目の条件を満たす.さらに,その中の幾つかのフィールドは変更可能なものになっている場合があり,起動してからいくつかのタイミングで更新される可能性がある.しかし,それほど頻繁な変更ではないため,2つ目の条件も満たすことになる.つまり,グローバルコンテキストは先ほど挙げた2点を満たしているのだ.このような状況設定だと,IORef と State モナドのパフォーマンスは同等になる場合が多い.例えば,次の例を見てみる:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | {-# LANGUAGE StrictData #-} data Context a = Context { subctx :: SubContext a , param1 :: Bool , param2 :: String , param3 :: Ordering , param4 :: Int } data SubContext a = SubContext { subparam1 :: a , subparam2 :: Bool , subparam3 :: String , subparam4 :: Ordering } initialContext :: a -> Context a initialContext x = Context { subctx = SubContext { subparam1 = x , subparam2 = False , subparam3 = "str1" , subparam4 = EQ } , param1 = True , param2 = "str2" , param3 = EQ , param4 = 0 } sumByState :: [Int] -> Context Int sumByState l = execState (go l 0) (initialContext 0) where go :: [Int] -> Integer -> State (Context Int) () go [] _ = pure () go (x:xs) i = case i of 10000 -> go xs $! i + 1 _ -> do goUpdate x go xs 0 goUpdate x = do ctx <- get let s = subparam1 (subctx ctx) + x put $! ctx { subctx = (subctx ctx) { subparam1 = s } } sumByIORef :: [Int] -> IO (Context (IORef Int)) sumByIORef l = do r <- newIORef 0 let ctx = initialContext r go ctx l 0 pure ctx where go :: Context (IORef Int) -> [Int] -> Integer -> IO () go _ [] _ = pure () go ctx (x:xs) i = case i of 10000 -> go ctx xs $! i + 1 _ -> do goUpdate ctx x go ctx xs 0 goUpdate ctx x = do let r = subparam1 $ subctx ctx s <- readIORef r writeIORef r $! s + x |
この例は色々細工がしてあるが,とにかくこの場合,入力リストの長さを 100000 より大きくすると,最適化レベル1 / 2 両方で, sumByIORef と sumByState は大体同等の性能か,IORef の方がほんの少し速くなる.細工の内容としては,
- コンテキストの更新の合間に,余計な Integer オブジェクトを作り出し GC させることで,コンテキストの内容自体の世代を成長させてから GC に回収させる.
- フィールドを多くすることで,State モナドの場合に更新に手間がかかるようにしている.
という感じ.この例は結構無理やり作っているけど,実際コンテキストはそこそこフィールドが多くネストしていて,書き込みが少ないことから内容も世代を超えやすいはずなので,現実の条件を擬似的に作り出してる例と言えると思う.よって,グローバルコンテキストに対し IORef を適用するならば,パフォーマンス的な心配はしなくて良いと言えるのではないだろうか? さらに,IORef が State モナドより勝る点として以下のものがある.
- 可変なフィールドを明示することができ,データ定義から可変な箇所がわかるようになる.
- 値の変更の際,State モナドでは読み込み,書き込み両方でデータのネスト構造を辿る必要があったのが,IORef では読み込みのみでよくなる.
今回の例は, Context Int をちゃんと書き下せば, subparam1 フィールドを unpack できる.この場合, IORef は boxed なものしか扱えないため,ちょっと不利かもしれないが,そこら辺も unboxed-ref 使えばいい勝負ができるんじゃないかなと思ってる (が,試してない.また時間があれば,試してみたい).
ただ注意として, writeIORef は局所的に頻繁に呼び出すような場面には向いてないので,その場合は一旦 IORef から取り出して再帰関数の累積引数として引き回したり,そういう時こそ State モナドで最終的な値を作ってから,IORef に入れ直すのが無難.更新の間に色々処理が挟まるようだったら, writeIORef や modifyIORef 使ってもいいかもねって感じ.
Reader + IORef
さて,先ほど挙げた sumByIORef は Reader モナドを使うと次のように書き換えられる:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import Control.Monad.Reader import Control.Monad.IO.Class type App = ReaderT (Context (IORef Int)) IO sumByIORef :: [Int] -> App () sumByIORef l = go l 0 where go :: [Int] -> Integer -> App () go [] _ = pure () go (x:xs) i = case i of 10000 -> go xs $! i + 1 _ -> do goUpdate x go xs 0 goUpdate x = do ctx <- ask let r = subparam1 $ subctx ctx s <- liftIO $ readIORef r liftIO $ writeIORef r $! s + x |
本来, State が補っていた部分を,読み込み部分は ReaderT に,可変部分は IORef と IO に任せる感じだ.このようなプログラミングスタイルは,何も僕が思いついたわけではなく, ReaderT パターン と呼ばれていて,結構最近は浸透しつつあるんかな? 今まで挙げたコードの清潔さを担保するという他にも,このスタイルはメリットがあり,もうちょっと周辺のツールも整備されてたりするんだけど,まあ詳細は 元記事 の方を読んでくれ.(飽きてきた.)
まとめ
というわけで,状態更新を行う時の代表手法として紹介される State モナドだけど,Reader + IORef を使った方が見通しがいい場合もあるよという話でした.パフォーマンス面での話は,誰も挙げていない気がしたので書いた感じ.
大雑把には,State モナドより Reader + IORef を使った方がいい場合として,状態が
- 大きくてネストしていたりというように,ほどほどに複雑で
- 頻繁には変更しなくて
- 局所的な変更が多くて (変更しない部分も多くて)
という条件を満たす時というのがある.この場合は,State よりも Reader + IORef の方がコードの簡潔さ的に良い場合があり,パフォーマンス面でもそこまで有意差はないよという感じ.今回は,IORef しか紹介しなかったけど,これは TVar とかにも通じる話だし,STRef 使えば全体として純粋に計算できる場合もある.ま,そういう感じで (ざつぅ).
誤りのあった主張
そもそもの目算として,ネストするような状態で奥深くを更新する場合は,IORef の方がパフォーマンス的にも優位なのではないかというのがあったんだけど,これはあまり大きな差ではなさそうだった.まず,当初この記事で挙げていた以下の例で,ネストする状態の分解と構成が重いため, sumByState より sumByIORef の方が速いという主張は誤りだった ( maoe さんの 指摘 で判明した. maoe さん,ありがとうございます).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | data Context a = Context { subctx :: SubContext a , param1 :: Bool , param2 :: String } data SubContext a = SubContext { subparam1 :: a , subparam2 :: Bool } initialContext x = Context { subctx = SubContext { subparam1 = x , subparam2 = False } , param1 = True , param2 = "" } sumByState :: [Int] -> Context Int sumByState l = execState (go l) (initialContext 0) where go [] = pure () go (x:xs) = do modify' \ctx -> ctx { subctx = (subctx ctx) { subparam1 = subparam1 (subctx ctx) + x } } go xs sumByIORef :: [Int] -> IO (Context (IORef Int)) sumByIORef l = do r <- newIORef 0 let ctx = initialContext r go ctx l pure ctx where go _ [] = pure () go ctx (x:xs) = do let r = subparam1 $ subctx ctx modifyIORef' r \s -> s + x go ctx xs |
この例で問題だったのは, sumByState の
1 2 3 4 5 | modify' \ctx -> ctx { subctx = (subctx ctx) { subparam1 = subparam1 (subctx ctx) + x } } |
の部分で,大幅に効率が悪かったのはこの部分でスペースリークが発生していたからだった.この場合 modify' が更新値を WHNF に評価しても,ネストした部分の subctx に入る値は評価されずサンクになる.このサンクは,最終的に返ってくる Context Int の値を NF に評価するまで積み上がり,その評価の時点で初めて潰されることになる.このスペースリークが, sumByState が遅くなっていた要因で,解決策は Context a / SubContext a を StrictData にするか,以下のように subparam1 に入れる値を NF にすれば良い:
1 2 3 4 5 6 7 | modify' \ctx -> let !s = subparam1 (subctx ctx) + x in ctx { subctx = (subctx ctx) { subparam1 = s } } |
こうすると, sumByState は sumByIORef より速くなり,パフォーマンスが改善するというのは誤りだったということになる.では,実際状態の分解と構成はまるっきり無視できるかというと,一応は影響するらしい.今回差し替えた,色々細工を加えた例では,最適化レベル1では 10% ほど sumByState が sumByIORef より性能が悪化するという結果になった.ところが,最適化レベル2になると,
1 2 3 4 5 6 7 | data A = A Int Int f :: A -> Int f = go where go (A 0 n2) = n2 go (A n1 n2) = go $ A n2 $ n1 - 1 |
を,
1 2 3 4 5 6 7 | data A = A Int Int f :: A -> Int f (A (I# n1#) (I# n2#)) = go n1# n2# where go 0# m2# = I# m2# go m1# m2# = go m2# $ m1# -# 1# |
にするような最適化 [3] が入り,ネストも平坦になるため一切分解と構成のオーバーヘッドはかからない.また,内部の値も unbox 化されるので,結構コスト削減になってるはずなのだが,代わりにかなり多くの引数を再帰関数で引き回す必要があるため,そこらへんがオーバーヘッドになって,結局 IORef と同程度にしかパフォーマンスが出せてないみたい (ちょっと詳細はまだ調査できていない).
とりあえず,当初の IORef の場合 State モナドに比べてパフォーマンスが改善する場合もあるというのは,事実となる場合もあるはあるがそこまで大きな有意差ではなく,書くコードと入る最適化によって十分覆る程度のものみたい.なので,パフォーマンスが改善するというよりは,パフォーマンスにそこまで有意差はないと言った方が実態に即している気がしたので,全体的に取り下げることにした.
| [1] | GHC では,GC の捕捉のため旧世代から新世代への参照が作られた場合の更新通知を,mutator が行う必要がある.この通知を write barrier と呼んでいて,writeMutVar# も write barrier を内部で行う.しかし,write barrier があまりにも多いと,内部の仕組み的に GC の性能が下がるという問題が知られている.一般に,GHC の GC は可変なオブジェクトについてあまり良いサポートを提供できていないと言う 話 もある.その意味では,純粋性を贔屓しているというのは正しい. |
| [2] | 最適化レベル0,つまり最適化なしの場合,IORef の方が速くなる現象にはここまで触れなかったが,実はこれは State のせいというより mtl のせいという側面が大きい.普段私たちはそこまで意識していないのだが,実は型クラスを使うのにはそれなりの実行時コストがかかる.これらは,最適化によってそれなりに排除されている.しかし,最適化なしの場合はこのコストはもろに影響してくる.今回の場合は, IO モナドだけを使ったコードと比較し, State モナドのコードは mtl の API を使ったので Monad 型クラスと MonadState 型クラスの抽象化に依存している.つまり,その分コストが増えてしまったということになる.なので,最適化なしの場合は,あまり本質的な違いとは言えないだろう. |
| [3] | データ型に対する w/w の一種みたい: https://gitlab.haskell.org/ghc/ghc/wikis/commentary/compiler/data-types#the-constructor-wrapper-functions |