monad への埋め込み
monoidal category (E,⋅,1) において,終対象 F∈∣E∣ が存在するとする.
graded monad (T:E→[C,C],η:Id⇒T1,μ:T−;T−⇒T(−⋅−) について, (T^:C→C,η^:Id⇒T^,μ^:T^2⇒T) を次のように与える.
- T^=TF
- η^A=AηAT1AT(1→F)T^A
- μ^A=T^2AμF,FT(F⋅F)AT(F⋅F→F)T^A
こいつは, monad になる.規則を満たすかは,次のように確認できる.
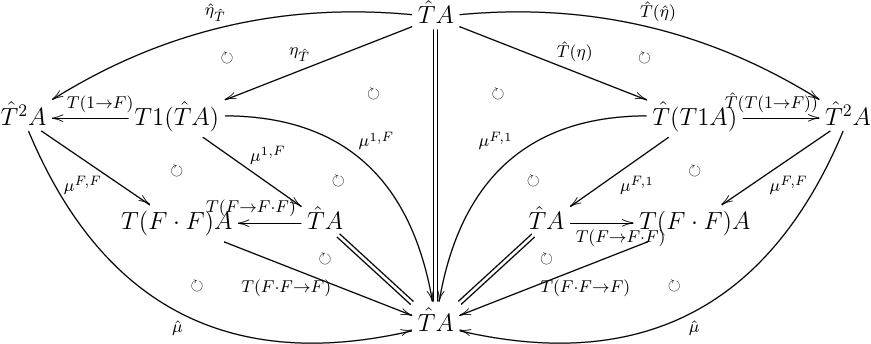
こちらは, η^T^;μ^=T^η^;μ^=id を計算したやつ.
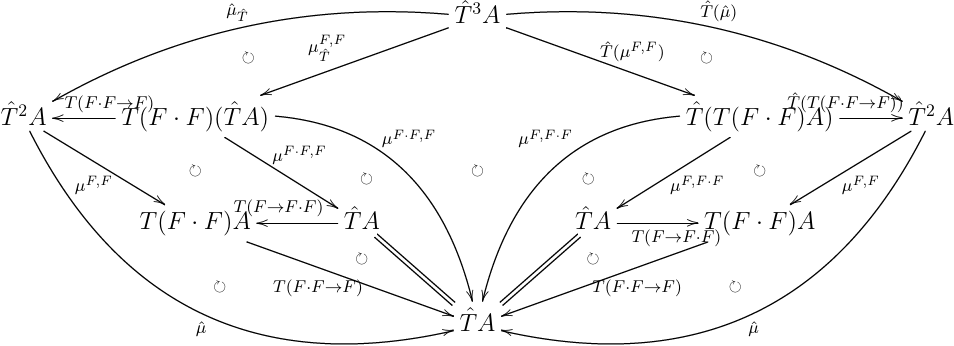
こちらは, μ^T^;μ^=T^μ^;μ^ を計算したやつ.
なお, μ:T−;T−⇒T(−⋅−):E×E→[C,C] は自然変換なので,以下を満たし,

F は終対象なので, FfF⋅FgF=idF なことに注意.
そして,自然変換 T(ϵ→F):T(ϵ)⇒T^ が存在する.
preordered monoid の終対象とは, preorder での最大元に当たる.なのでこの埋め込みは,エフェクトシステム的な直感にもマッチしていて,エフェクトシステムがエフェクトの見積もりを細かくして型に情報として載せるものだったわけだけど,その細かく見積もった情報を実行時に使わないで,最大のエフェクトで動作だけ近似するというわけだ.
埋め込みによる意味論の保存
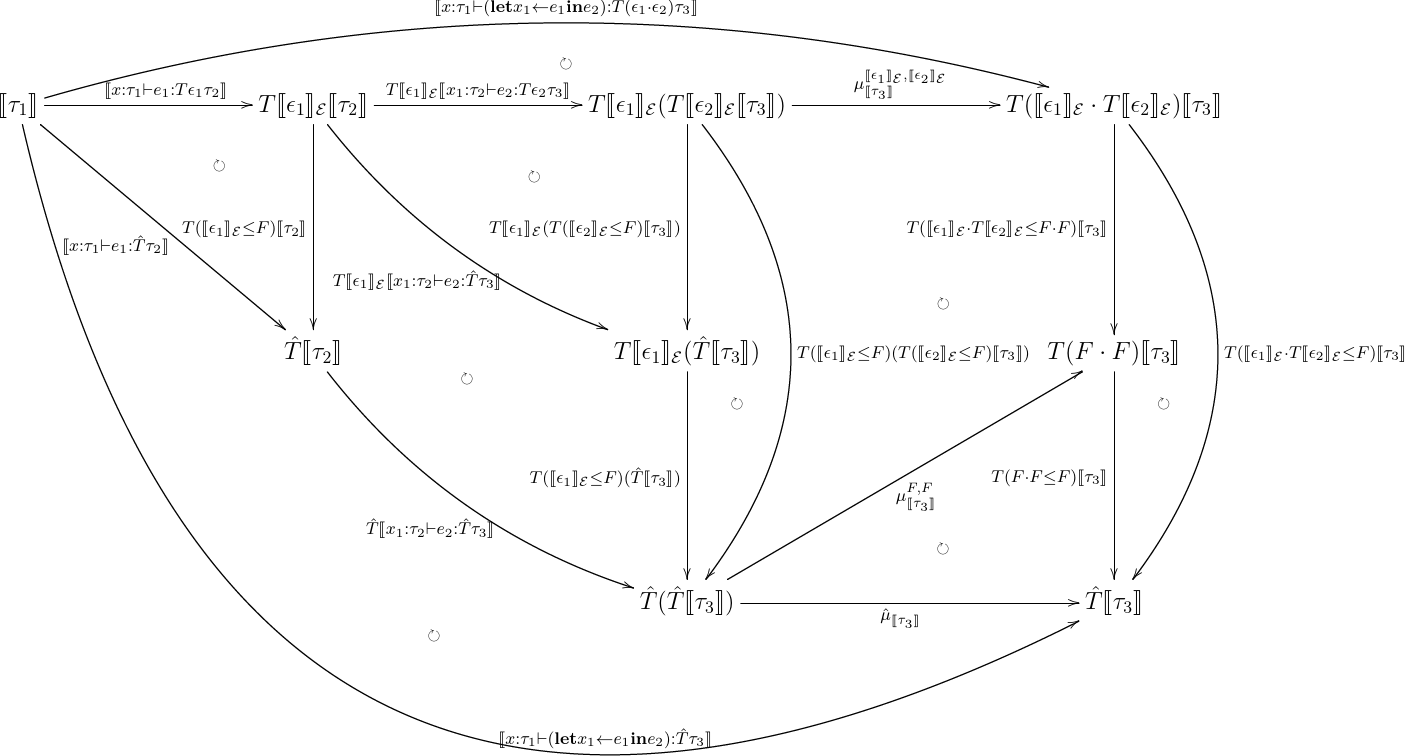
もちろんこの埋め込みが, graded monadic な意味論を monadic な意味論にうまく近似できなければ意味がない.なので,それを確かめてみる.近似できるとは,つまり以下のものが成り立つということだ.
[[x:τ1⊢e:Tϵτ2]];i[[τ2]]=[[x:τ1⊢e:T^τ2]]
左側が graded monadic な意味論,右側が monadic な意味論になる.ここで, i:T[[e]]E⇒T^ は埋め込み T(ϵ→F) になる. 以前の記事 で上げた構文要素それぞれで,帰納法を回してこれが一致することを示してみる.なお, effect を発生させる関数は graded monad での意味論と monad での意味論で解釈が異なる.なので,こいつらについては,
[[f:τ1ϵτ2]];i[[τ2]]=[[f:τ1→T^τ2]]
が成り立つという仮定を置く.この下で,以下のように帰納法を用いて示すことができる.
- lift
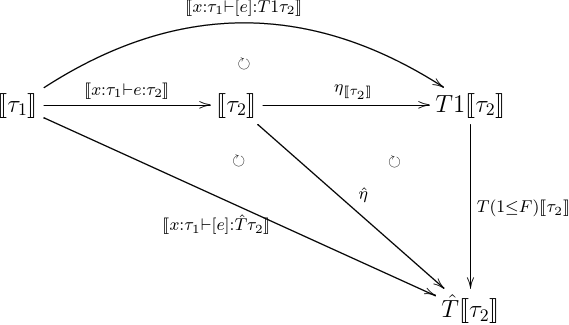
- effectful app
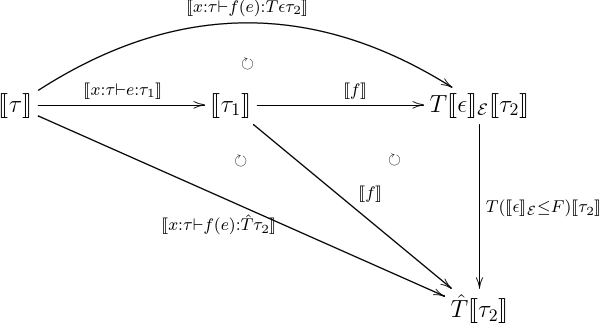
- let
- cast
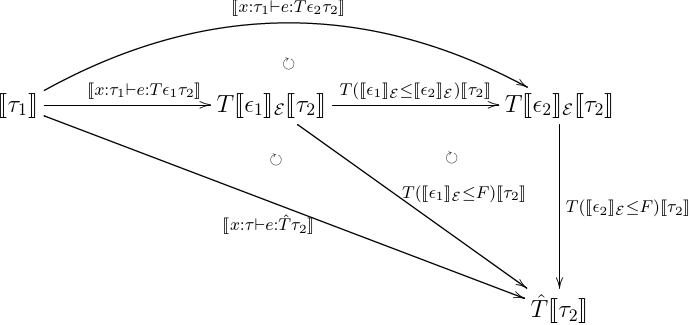
ちゃんと成り立ってるっぽい.