Scala コードの裏側
2019年04月24日に投稿 (2020年03月29日に更新) • カテゴリ:プログラミング言語
先日, Scala コードの裏側について幾つか話を聞いた.で,気になったので実際に JVM コードを出して,色々見てみることにした.なお,当方 Scala 初心者なので,おそらくかなり間違いを含んでるのと,普段使いの感覚からは離れてる部分はあると思うので,そこら辺は注意して読んでくれって感じ.
Scala コンパイラの概要
Scala コンパイラが実際どういう処理をしてるのか知らなかったので,まずはその辺を調べた. Scala は,プログラムを複数のフェーズに分けてコンパイルし,最終的に JVM のコードを吐き出すっぽい.コンパイルフェーズは,以下のコマンドで見れるっぽい [1]:
$ scalac -Xshow-phases
phase name id description
---------- -- -----------
parser 1 parse source into ASTs, perform simple desugaring
namer 2 resolve names, attach symbols to named trees
packageobjects 3 load package objects
typer 4 the meat and potatoes: type the trees
patmat 5 translate match expressions
superaccessors 6 add super accessors in traits and nested classes
extmethods 7 add extension methods for inline classes
pickler 8 serialize symbol tables
refchecks 9 reference/override checking, translate nested objects
uncurry 10 uncurry, translate function values to anonymous classes
fields 11 synthesize accessors and fields, add bitmaps for lazy vals
tailcalls 12 replace tail calls by jumps
specialize 13 @specialized-driven class and method specialization
explicitouter 14 this refs to outer pointers
erasure 15 erase types, add interfaces for traits
posterasure 16 clean up erased inline classes
lambdalift 17 move nested functions to top level
constructors 18 move field definitions into constructors
flatten 19 eliminate inner classes
mixin 20 mixin composition
cleanup 21 platform-specific cleanups, generate reflective calls
delambdafy 22 remove lambdas
jvm 23 generate JVM bytecode
terminal 24 the last phase during a compilation run
各フェーズは, scala.reflect.apis.Trees に定義されている構成子を使って作成された構文木を,変換していく.それぞれのフェーズが出力する木は,次のようにして見れる:
$ cat src/TestSource.scala
object TestSource {
def testSource(a: Long): Long = {
val b = a + 1
b
}
}
$ scalac -Ystop-after:parser -Xprint:parser src/TestSource.scala
[[syntax trees at end of parser]] // TestSource.scala
package <empty> {
object TestSource extends scala.AnyRef {
def <init>() = {
super.<init>();
()
};
def testSource(a: Long): Long = {
val b = a.$plus(1);
b
}
}
}
また,構文木を GUI で見るためのオプションも用意されている:
$ cat src/TestSource.scala
object TestSource {
def testSource(a: Long): Long = {
val b = a + 1
b
}
}
$ scalac -Ystop-after:parser -Ybrowse:parser src/TestSource.scala
こうすると,以下の画面が表示される:
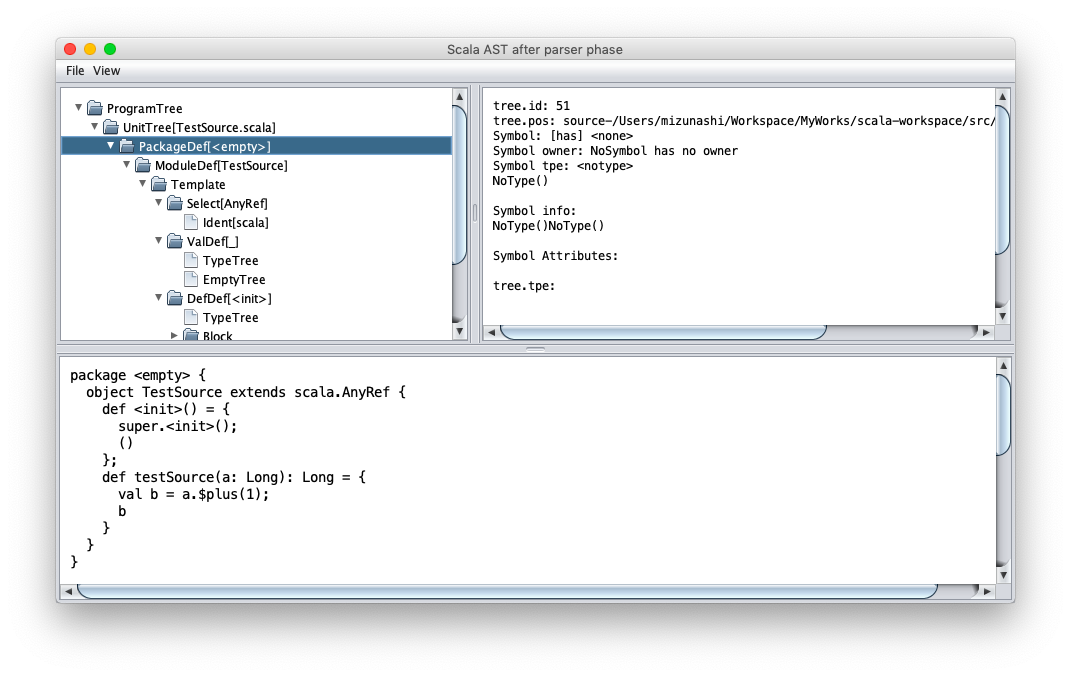
では, Scala コードが実際にどういう JVM コードを出すのか見ていきたいと思う.なお,試した環境は,以下の通り:
| Scala のバージョン | 2.12.8 |
| Java Runtime のバージョン | Java(TM) SE Runtime Environment 1.8.0_131 |
| Java Hotspot のバージョン | Java HotSpot(TM) 64-Bit Server VM 25.131 |
末尾呼び出し最適化
Java は末尾呼び出し最適化をしないことで有名だ [2].だけど, Scala は末尾呼び出し最適化を行う.具体的にコードを見てみる:
$ cat src/TailCallOpt.scala
object TailCallOpt {
def tailCallFunc(a: Long): Long = {
if (a > 10) a else tailCallFunc(a + 1)
}
}
$ scalac -Ystop-after:tailcalls -Xprint:fields,tailcalls src/TailCallOpt.scala
[[syntax trees at end of fields]] // TailCallOpt.scala
package <empty> {
object TailCallOpt extends Object {
def <init>(): TailCallOpt.type = {
TailCallOpt.super.<init>();
()
};
def tailCallFunc(a: Long): Long = if (a.>(10))
a
else
TailCallOpt.this.tailCallFunc(a.+(1))
}
}
[[syntax trees at end of tailcalls]] // TailCallOpt.scala
package <empty> {
object TailCallOpt extends Object {
def <init>(): TailCallOpt.type = {
TailCallOpt.super.<init>();
()
};
def tailCallFunc(a: Long): Long = {
<synthetic> val _$this: TailCallOpt.type = TailCallOpt.this;
_tailCallFunc(_$this: TailCallOpt.type, a: Long){
if (a.>(10))
a
else
_tailCallFunc(TailCallOpt.this, a.+(1).asInstanceOf[Long]()).asInstanceOf[Long]()
}
}
}
}
この最適化は名前の通り, tailcalls フェーズで行われる.実は Scala 内部では ラベル式 という構文が存在する. Scala のプログラム的にはこの式は書けないが,構文木上は用意されていて,最終的にジャンプに変換される.今回のも, tailCallFunc の中身はこのラベル式を使って変換されている.以下の部分がそう:
_tailCallFunc(_$this: TailCallOpt.type, a: Long) {
if (a.>(10))
a
else
_tailCallFunc(TailCallOpt.this, a.+(1).asInstanceOf[Long]()).asInstanceOf[Long]()
}
実際に,対応する JVM のバイトコードを見てみる:
$ scalac src/TailCallOpt.scala
$ ls -D
'TailCallOpt$.class' TailCallOpt.class src/
$ javap -v -c 'TailCallOpt$.class'
...
public long tailCallFunc(long);
descriptor: (J)J
flags: ACC_PUBLIC
Code:
stack=4, locals=3, args_size=2
0: lload_1
1: ldc2_w #16 // long 10l
4: lcmp
5: ifle 12
8: lload_1
9: goto 19
12: lload_1
13: lconst_1
14: ladd
15: lstore_1
16: goto 0
19: lreturn
...
javap は Java の逆アセンブラ. -v をつけると詳細に情報を表示してくれる.で,コードの読み方だけど,まずは JVM の基本事項から:
- メソッドごとに ローカル変数テーブル が用意されている.初期状態では,メソッドの引数が順番に入る.なお, double と long はテーブルの 2 行分領域を取る.
- 定数は,クラスそれぞれに用意されている 定数プール に,添字と型付きで格納される.添字は, #[数字] の形で表される.
- JVM は 1 スタックで動く.
他にも重要なことは一杯あるんだけど,とりあえずコードを読むために上のことは押さえておいてくれって感じ.で,具体的な命令の内容だけど,以下のようになる:
// ローカル変数テーブルの 1 番目を, long 値としてスタックに積む 0: lload_1 // 定数プールから値 (``#16`` にはコメントで書かれてる通り, ``10L`` が入っている) を呼び出し,スタックに積む 1: ldc2_w #16 // long 10l // スタックから 2 要素取り出し, long 値として比較した結果をスタックに積む 4: lcmp // 比較結果が「以下」であれば, 12 バイト目に飛ぶ 5: ifle 12 // ローカル変数テーブルの 1 番目を, long 値としてスタックに積む 8: lload_1 // 19 バイト目に飛ぶ 9: goto 19 // ローカル変数テーブルの 1 番目を, long 値としてスタックに積む 12: lload_1 // long 値 1 を,スタックに積む 13: lconst_1 // スタックから 2 要素取り出し,加算した結果をスタックに積む 14: ladd // スタックから 1 要素取り出し, long 値としてローカル変数テーブルの 1 番目に格納する 15: lstore_1 // 0 バイト目に飛ぶ 16: goto 0 // スタックに返り値として long 値を残して,呼び出し元に戻る 19: lreturn
もう少し分かりやすいよう, C 言語風に書き直してみると,以下のようになる:
long tailCallFunc(void *a0, long a1) {
const long tmp = 10L;
START:
if (a1 <= tmp) {
goto END;
}
a1 = a1 + 1;
goto START;
END:
return a1;
}
完全に一対一対応するわけではないが,大体やってることはこんな感じ.最初の引数は, this が入ることに注意.なんしろ,末尾再帰は goto を使ってただのループに変換されてることが分かると思う.なお, while などもラベル式に変換された後,同じように goto を使った JVM コードが出される. Scala だと, tailrec アノテーションを使うことで,末尾呼び出し最適化が行われる形になってるかチェックすることもできる:
import scala.annotation.tailrec
object TailCallOpt {
@tailrec
def tailCallFunc(a: Long): Long = {
if (a > 10) a else tailCallFunc(a + 1)
}
}
大域脱出
Scala には,大域リターン(non local return)という機能がある.実は僕はこの機能を知らなかったんだけど,以下のようなやつ:
def func(): Long = {
List(1, 2, 3) foreach { x =>
if (x > 2) return 1
}
return 0
}
foreach メソッドが受け取っている無名関数の中で return を書くと,外側のメソッドが抜ける.ただ, Java では C で言う所の setjmp / longjmp 機能がない.これを実際にどう実現するかなんだけど,有名な方法があって,スタックトレースを消した例外をハンドリングする. Scala ではこの方法が用いられてる [3] .実際にコード生成を見てみると以下のようになる:
$ cat src/NonLocalReturn.scala
object NonLocalReturn {
def nonLocalReturn(): Long = {
List(1L, 2L, 3L) foreach { x =>
if (x > 2) return x
}
return 0
}
}
$ scalac -Ystop-after:uncurry -Xprint:refchecks,uncurry src/NonLocalReturn.scala
[[syntax trees at end of refchecks]] // NonLocalReturn.scala
package <empty> {
object NonLocalReturn extends scala.AnyRef {
def <init>(): NonLocalReturn.type = {
NonLocalReturn.super.<init>();
()
};
def nonLocalReturn(): Long = {
scala.collection.immutable.List.apply[Long](1L, 2L, 3L).foreach[Unit](((x: Long) => if (x.>(2))
return x
else
()));
return 0L
}
}
}
[[syntax trees at end of uncurry]] // NonLocalReturn.scala
package <empty> {
object NonLocalReturn extends Object {
def <init>(): NonLocalReturn.type = {
NonLocalReturn.super.<init>();
()
};
def nonLocalReturn(): Long = {
<synthetic> val nonLocalReturnKey1: Object = new Object();
try {
scala.collection.immutable.List.apply[Long](scala.Predef.wrapLongArray(Array[Long]{1L, 2L, 3L})).foreach[Unit]({
final <artifact> def $anonfun$nonLocalReturn(x: Long): Unit = if (x.>(2))
throw new scala.runtime.NonLocalReturnControl[Long](nonLocalReturnKey1, x)
else
();
((x: Long) => $anonfun$nonLocalReturn(x))
});
return 0L
} catch {
case (ex @ (_: scala.runtime.NonLocalReturnControl[Long @unchecked])) => if (ex.key().eq(nonLocalReturnKey1))
ex.value()
else
throw ex
}
}
}
}
この変換は uncurry フェーズで行われるっぽい.大域リターンが, NonLocalReturnControl 例外のハンドリングに変換されていることが分かる. return は NonLocalReturnControl の throw に変換し,外側で catch してその値を return している. NonLocalReturnControl はスタックトレースを生成しないために, fillInStackTrace を書き換えてる.定義は以下のようになっている [4]:
import scala.util.control.ControlThrowable
class NonLocalReturnControl[@specialized T](val key: AnyRef, val value: T) extends ControlThrowable {
final override def fillInStackTrace(): Throwable = this
}
ところで余談だけど, Scala の無名関数はこの後ラムダリフティング (lambdalift) によって final method に変換され,ラムダ除去 (delambdafy) によって Java の Single Abstract Method (SAM) が使える形に変換される.今回の例をそのまま使うと,例外ハンドリングによってかなりノイズが大きくなるので,もう少し簡略化した例で示すと以下の感じ:
$ cat src/Lambda.scala
object Lambda {
def func(a: Long) {
List(1L, 2L, 3L) foreach { x => x + a }
}
}
$ scalac -Ystop-after:jvm -Xprint:uncurry,lambdalift,delambdafy,jvm src/Lambda.scala
[[syntax trees at end of uncurry]] // Lambda.scala
package <empty> {
object Lambda extends Object {
def <init>(): Lambda.type = {
Lambda.super.<init>();
()
};
def func(a: Long): Unit = scala.collection.immutable.List.apply[Long](scala.Predef.wrapLongArray(Array[Long]{1L, 2L, 3L})).foreach[Long]({
final <artifact> def $anonfun$func(x: Long): Long = x.+(a);
((x: Long) => $anonfun$func(x))
})
}
}
[[syntax trees at end of lambdalift]] // Lambda.scala
package <empty> {
object Lambda extends Object {
def <init>(): Lambda.type = {
Lambda.super.<init>();
()
};
def func(a: Long): Unit = scala.collection.immutable.List.apply(scala.Predef.wrapLongArray(Array[Long]{1L, 2L, 3L})).foreach({
((x: Long) => Lambda.this.$anonfun$func$1(a, x))
});
final <artifact> private[this] def $anonfun$func$1(a$1: Long, x: Long): Long = x.+(a$1)
}
}
[[syntax trees at end of delambdafy]] // Lambda.scala
package <empty> {
object Lambda extends Object {
def func(a: Long): Unit = scala.collection.immutable.List.apply(scala.Predef.wrapLongArray(Array[Long]{1L, 2L, 3L})).foreach({
$anonfun(a)
});
final <static> <artifact> def $anonfun$func$1(a$1: Long, x: Long): Long = x.+(a$1);
def <init>(): Lambda.type = {
Lambda.super.<init>();
()
}
}
}
[[syntax trees at end of jvm]] // Lambda.scala: tree is unchanged since delambdafy
$anonfun(a) が $anonfun$func$1 final method を使った SAM の呼び出しに置換される.うちの環境だと,最終的に次のような JVM コードが出される:
$ javap -p -v -c 'Lambda$.class'
...
public void func(long);
descriptor: (J)V
flags: ACC_PUBLIC
Code:
stack=7, locals=3, args_size=2
0: getstatic #25 // Field scala/collection/immutable/List$.MODULE$:Lscala/collection/immutable/List$;
3: getstatic #30 // Field scala/Predef$.MODULE$:Lscala/Predef$;
6: iconst_3
7: newarray long
9: dup
10: iconst_0
11: lconst_1
12: lastore
13: dup
14: iconst_1
15: ldc2_w #31 // long 2l
18: lastore
19: dup
20: iconst_2
21: ldc2_w #33 // long 3l
24: lastore
25: invokevirtual #38 // Method scala/Predef$.wrapLongArray:([J)Lscala/collection/mutable/WrappedArray;
28: invokevirtual #42 // Method scala/collection/immutable/List$.apply:(Lscala/collection/Seq;)Lscala/collection/immutable/List;
31: lload_1
32: invokedynamic #64, 0 // InvokeDynamic #0:apply$mcJJ$sp:(J)Lscala/runtime/java8/JFunction1$mcJJ$sp;
37: invokevirtual #70 // Method scala/collection/immutable/List.foreach:(Lscala/Function1;)V
40: return
...
BootstrapMethods:
0: #60 invokestatic java/lang/invoke/LambdaMetafactory.altMetafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
Method arguments:
#44 (J)J
#49 invokestatic Lambda$.$anonfun$func$1:(JJ)J
#44 (J)J
#50 3
#51 1
#53 scala/Serializable
1: #86 invokestatic scala/runtime/LambdaDeserialize.bootstrap:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;[Ljava/lang/invoke/MethodHandle;)Ljava/lang/invoke/CallSite;
...
詳しい説明は省略するが,注目して欲しいのは 32 バイト目の invokedynamic で呼ばれてるやつ. invokedynamic は SAM 向けに Java8 から新たに導入された命令で [5],1番目に SAM の元となるクラスメソッド,2番目にブートストラップメソッドの番号を受け取って,ブートストラップメソッドから生成したメソッドを呼び出す.なお, 2 回目からはブートストラップメソッドは呼び出されず,作ったメソッドを直接呼び出すことで効率が良くなるとかがあるらしい.なお,ここで SAM の元となるオブジェクトに scala/runtime/java8/JFunction1$mcJJ$sp というのが指定されているのが分かると思う. Scala では生成する SAM の型によって幾つかテンプレートを用意しているようで, JFunction1$mcJJ$sp はメソッドの型が (v1: Long): Long となるやつに対するテンプレートになっている.こうすると何が良いのかいまいち分からないけど,きっと効率が良くなるか invokedynamic の制約かなんかなんだろうなあ (適当) .
lazy val のパフォーマンス
最後に lazy val について.これは,話を聞く前から気になってたんだけど, Scala の lazy val は大変遅いという噂をよく聞く.で,具体的にどんくらい遅いのか,何が原因なのかをちょっと調べてみた.まず, lazy val は,最終的にどのようなコードに変換されるのかを見てみる.まず, Scala の各フェーズの変換から:
$ cat src/LazyVal.scala
object LazyVal {
def func(a: Int): Int = {
lazy val v = a + 1
v + 2
}
}
$ scalac -Ystop-after:jvm -Xprint:uncurry,fields,jvm src/LazyVal.scala
[[syntax trees at end of uncurry]] // LazyVal.scala
package <empty> {
object LazyVal extends Object {
def <init>(): LazyVal.type = {
LazyVal.super.<init>();
()
};
def func(a: Int): Int = {
<stable> <accessor> lazy val v: Int = a.+(1);
v().+(2)
}
}
}
[[syntax trees at end of fields]] // LazyVal.scala
package <empty> {
object LazyVal extends Object {
def <init>(): LazyVal.type = {
LazyVal.super.<init>();
()
};
def func(a: Int): Int = {
lazy <artifact> val v$lzy: scala.runtime.LazyInt = new scala.runtime.LazyInt();
<artifact> private def v$lzycompute(): Int = v$lzy.synchronized[Int](if (v$lzy.initialized())
v$lzy.value()
else
v$lzy.initialize(a.+(1)));
lazy def v(): Int = if (v$lzy.initialized())
v$lzy.value()
else
v$lzycompute();
v().+(2)
}
}
}
[[syntax trees at end of jvm]] // LazyVal.scala
package <empty> {
object LazyVal extends Object {
def func(a: Int): Int = {
lazy <artifact> val v$lzy: scala.runtime.LazyInt = new scala.runtime.LazyInt();
LazyVal.this.v$1(v$lzy, a).+(2)
};
final <static> <artifact> private[this] def v$lzycompute$1(v$lzy$1: scala.runtime.LazyInt, a$1: Int): Int = v$lzy$1.synchronized(if (v$lzy$1.initialized())
v$lzy$1.value()
else
v$lzy$1.initialize(a$1.+(1)));
final <static> lazy private[this] def v$1(v$lzy$1: scala.runtime.LazyInt, a$1: Int): Int = if (v$lzy$1.initialized())
v$lzy$1.value()
else
LazyVal.this.v$lzycompute$1(v$lzy$1, a$1);
def <init>(): LazyVal.type = {
LazyVal.super.<init>();
()
}
}
}
Int 型の lazy val の場合素直に,初期化されているかチェックして初期化されていなければ計算を実行し結果を保存して返す,されていれば保存した値をそのまま返すみたいなことをするオブジェクトを返してるっぽい.ただ,初期化は複数のスレッドから呼び出されると競合が起きるので synchronized を指定して競合を防いでいる.ただ, synchronized は重いので,単に synchronized で初期化するわけではなく,まず単に初期化されているかを確認し,されていなければもう一度 synchronized で確認を行う test and test-and-set みたいなことをしている.最終的にはラムダリフティングとラムダ除去によって,両方 final method として外に出されるっぽい.まあただこのコードならある程度 JVM で出されるコードは予想がつく.実際にコードを見てみる:
$ javap -p -v -c 'LazyVal$.class'
...
private static final int v$lzycompute$1(scala.runtime.LazyInt, int);
descriptor: (Lscala/runtime/LazyInt;I)I
flags: ACC_PRIVATE, ACC_STATIC, ACC_FINAL, ACC_SYNTHETIC
Code:
stack=3, locals=4, args_size=2
0: aload_0
1: dup
2: astore_2
3: monitorenter
4: aload_0
5: invokevirtual #33 // Method scala/runtime/LazyInt.initialized:()Z
8: ifeq 18
11: aload_0
12: invokevirtual #37 // Method scala/runtime/LazyInt.value:()I
15: goto 25
18: aload_0
19: iload_1
20: iconst_1
21: iadd
22: invokevirtual #40 // Method scala/runtime/LazyInt.initialize:(I)I
25: istore_3
26: aload_2
27: monitorexit
28: iload_3
29: goto 35
32: aload_2
33: monitorexit
34: athrow
35: ireturn
...
public int func(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=2
0: new #17 // class scala/runtime/LazyInt
3: dup
4: invokespecial #18 // Method scala/runtime/LazyInt."<init>":()V
7: astore_2
8: aload_2
9: iload_1
10: invokestatic #22 // Method v$1:(Lscala/runtime/LazyInt;I)I
13: iconst_2
14: iadd
15: ireturn
...
v$1 メソッドについては省略した.気になる人は実際に見てくれって感じ. func の中身はほぼそのままって感じだ.問題は, v$lzycompute$1 で,なんか色々しとる.とりあえず, monitorenter / monitorexit が synchronized に対応するっぽい.で,これらはロック機構を提供するわけだけど計算中に例外が発生することもあるので,例外が起きた場合にちゃんと monitorexit を走らせないとデッドロック状態になってしまう可能性があるため,そこらへんを解決するコードも入ってるのかな?
さて, lazy val の中身を見たところで,パフォーマンス上気になるのは,以下の 3 点だ:
- LazyInt を介するため Boxing が挟まる
- monitorenter / monitorexit により,ロック処理が挟まる
- monitorenter を挟む際の,例外対処の処理が挟まる
このうちどれが大きな問題となるんだろう? とりあえず,まず大雑把に試してみる:
$ cat src/LazyValBenchmark.scala
object LazyValBenchmark {
def main(args: Array[String]) {
createLazyVal(10)
createVal(10)
refLazyVal(10)
refVal(10)
println("Warmup end")
{
val start = System.nanoTime();
val r = createVal(0)
val end = System.nanoTime()
println((end - start) + ":" + r)
}
{
val start = System.nanoTime();
val r = createLazyVal(0)
val end = System.nanoTime()
println((end - start) + ":" + r)
}
{
val start = System.nanoTime();
val r = refLazyVal(0)
val end = System.nanoTime()
println((end - start) + ":" + r)
}
{
val start = System.nanoTime();
val r = refVal(0)
val end = System.nanoTime()
println((end - start) + ":" + r)
}
}
val n1 = 1000000000
def createLazyVal(i0: Int): Int = {
var r = 0
while (r < n1) {
lazy val i = i0 + 1
r += i
}
r
}
def createVal(i0: Int): Int = {
var r = 0
while (r < n1) {
val i = i0 + 1
r += i
}
r
}
val n2 = n1
def refLazyVal(i0: Int): Int = {
lazy val i = i0 + 1
var r = 0
while (r < n2) {
r += i
}
r
}
def refVal(i0: Int): Int = {
val i = i0 + 1
var r = 0
while (r < n2) {
r += i
}
r
}
}
$ scalac src/LazyValBenchmark.scala
$ scala LazyValBenchmark
Warmup end
631499976:1000000000
6602310567:1000000000
792000315:1000000000
316664620:1000000000
$ scala LazyValBenchmark
Warmup end
635872302:1000000000
6604901477:1000000000
793790967:1000000000
316887105:1000000000
$ scala LazyValBenchmark
Warmup end
635827311:1000000000
6620801173:1000000000
795464679:1000000000
326651550:1000000000
だいぶ飽きてきたので, System.nanoTime 使って適当に済ませてる.よいこは真似しちゃダメだぞっ.結果はまず, lazy val を単に作って参照するだけで,普通の val より 10 倍差ぐらい付いてる.また参照するだけでも 2.6 倍差ぐらい.ただ, while ループとかカウンタとかの固定処理も入っていて結構ガバガバベンチマークではあるので,その結果でこの差ということはかなり性能差がありそう.
refLazyVal と refVal の差は,大体 Boxing の差と言えるだろうから, Int 以外で試すともうちょっと結果が変わってくるのかもしれない.疲れたので,今日はそこまでの調査は諦め.まあ, Int そのままだと, iload / istore 命令が使えるのに比べ, lazy val は保存してる値を v 関数と value メソッドを invoke して取りに行かなきゃいけないので差が付くのは仕方ない感がある.ただ, lazy val を何回も参照するなら一旦結果を val に入れた方がいいかもしれないと思うぐらいの差はありそう.
createLazyVal と createVal の差に refLazyVal と refVal の差を考慮して考えても,作成と初期化のコストはかなり重いっぽい.作成か初期化どちらが重いか,どちらも重いのかはもう疲れたのでいつかやれたら計ってみたいけど,多分 synchronized が大きく効いてるんだろう.これってスレッドセーフじゃなくていいから,もうちょっと速い lazy val を使いたいみたいな需要はないんだろうか? ガバガバベンチの結果をもとにすれば, lazy val 使うより変数複数管理する方が軽そうだけど.
まとめ
Scala のコード生成について,今までちゃんと見たことはなかったので,色々試した結果聞いてた噂と同じところ,違うところが知れて良かった.
普段 Haskell 使いの身としては, Haskell は最適化をゴリゴリやるので Scala はあんまり最適化しない印象を受けた.リフレクションのためとかなのかな.後, -Ybrowse 便利. GUI が Java 上だとプラットフォーム関係なしに書けるの,こういう時にも効いてくるんすね.
ちょっと力尽きた感あるので,また時間あったら色々調べてみたいですね
| [1] | sbt で scalac 入れてくれないっぽいので, scalac コマンドを使いたかったら Scala コンパイラを別途に入れる必要があるっぽい. |
| [2] | 理由はよく分からない. https://softwareengineering.stackexchange.com/a/272086 を読む限りでは,正直特に理由はなくて歴史的事情感がある. |
| [3] | という話を最近知った.それまでこんなテクニック,実際使われてるんかと思ってた. |
| [4] | https://github.com/scala/scala/blob/v2.12.8/src/library/scala/runtime/NonLocalReturnControl.scala |
| [5] | 一応 Java7 から存在してはいたらしいけど,本格的に使われ始めたのは Java8 から |