Apache Spark のお試し環境を作る
2019年05月21日に投稿 (2020年03月29日に更新) • カテゴリ:環境構築
Spark は spark-shell という対話式のお試し環境がついていて,かなりちょっと実行してみる系がやりやすそう.なので,そのための環境を Docker で作った.その備忘録.
なお, https://github.com/Semantive/docker-spark を参考にさせてもらった.と言っても,最終的にかなり似通ったものになってしまったが.
Docker の初期設定を書く
基本的な構成は,
- Dockerfile : Hadoop と Spark が入ったイメージの設定
- docker-compose.yml : master と worker の協調動作の設定
- scripts/entrypoint.bash : イメージを起動した時の実行スクリプト
にする.ベースイメージとしては, openjdk:8-jre を使う:
FROM openjdk:8-jre
元々は openjdk:9-jre で試してみてたんだけど, Spark の起動時に次のような警告が出るので,
WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.3.jar) to method java.nio.Bits.unaligned() WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release
一応 8 にバージョンを落としとくことにした. openjdk のイメージは, Debian をベースに作られてる.なので,まず Debian 用の初期設定コードを書いておく:
RUN apt-get update \
&& DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \
apt-utils locales wget \
&& update-locale LANG=C.UTF-8 LC_MESSAGES=POSIX \
&& locale-gen en_US.UTF-8 \
&& DEBIAN_FRONTEND=noninteractive dpkg-reconfigure locales \
&& rm -rf /var/lib/apt/lists/*
Hadoop と Spark のインストール
次は, Hadoop と Spark のインストール設定.公式のプレビルドアーカイブを使う.両者,設定は大体一緒. Hadoop の方は次の感じになる:
ENV HADOOP_VERSION="2.7.7" \
HADOOP_CHECKSUM="17c8917211dd4c25f78bf60130a390f9e273b0149737094e45f4ae5c917b1174b97eb90818c5df068e607835120126281bcc07514f38bd7fd3cb8e9d3db1bdde" \
HADOOP_INSTALL_DIR="/opt/hadoop"
ENV HADOOP_HOME="${HADOOP_INSTALL_DIR}" \
HADOOP_CONF_DIR="${SPARK_INSTALL_DIR}/etc/hadoop"
RUN useradd --system --create-home --home-dir "${HADOOP_HOME}" hadoop \
&& mkdir -p "${HADOOP_INSTALL_DIR}" \
&& cd "${HADOOP_INSTALL_DIR}" \
&& wget -q -O "${HADOOP_INSTALL_DIR}/hadoop.tgz" "https://archive.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz" \
&& sha512sum "hadoop.tgz" | grep "${HADOOP_CHECKSUM}" \
&& tar -xz --strip 1 -f "hadoop.tgz" \
&& chown -R hadoop:hadoop "${HADOOP_HOME}"
hadoop システムユーザを作り,公式からアーカイブを落としてきて,チェックサムで検査して,展開し,所有権を hadoop ユーザにする.落としてくる場所は, /opt/hadoop ディレクトリ.なお, HADOOP_HOME などがちゃんと設定されていないと, Spark が動かない. Spark の方は,次のように設定する:
ENV SPARK_VERSION="2.4.3" \
SPARK_CHECKSUM="e8b7f9e1dec868282cadcad81599038a22f48fb597d44af1b13fcc76b7dacd2a1caf431f95e394e1227066087e3ce6c2137c4abaf60c60076b78f959074ff2ad" \
SPARK_INSTALL_DIR="/opt/spark"
ENV SPARK_HOME="${SPARK_INSTALL_DIR}" \
SPARK_CONF_DIR="${SPARK_INSTALL_DIR}/conf"
RUN useradd --system --create-home --home-dir "${SPARK_HOME}" spark \
&& mkdir -p "${SPARK_INSTALL_DIR}" \
&& cd "${SPARK_INSTALL_DIR}" \
&& wget -q -O "${SPARK_INSTALL_DIR}/spark-bin-hadoop.tgz" "https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION%.*}.tgz" \
&& sha512sum "spark-bin-hadoop.tgz" | grep "${SPARK_CHECKSUM}" \
&& tar -xz --strip 1 -f "spark-bin-hadoop.tgz" \
&& chown -R spark:spark "${SPARK_HOME}"
見ての通り, Hadoop とほぼ同じだ.後は, エントリーポイントを書いて設定するだけ.ただ,それだけだとちょっと不便なので次の設定も書いておく:
ENV PATH="${SPARK_INSTALL_DIR}/bin:${PATH}" \
LD_LIBRARY_PATH="${HADOOP_HOME}/lib/native:${LD_LIBRARY_PATH}"
PATH の設定は, spark-shell などを実行パスに含める為.二つ目の設定は,書かないと次の警告が発生する:
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
エントリーポイントの設定
エントリーポイントとして,次のバッシュスクリプト scripts/entrypoint.bash を作成した:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #!/usr/bin/env bash [[ "$DEBUG" == "true" ]] && set -x [[ "$STRICT" == "true" ]] && set -u set -eo pipefail case ${1} in master) shift 1 exec "${SPARK_INSTALL_DIR}/bin/spark-class" "org.apache.spark.deploy.master.Master" "$@" ;; worker) shift 1 exec "${SPARK_INSTALL_DIR}/bin/spark-class" "org.apache.spark.deploy.worker.Worker" "$@" ;; *) exec "$@" ;; esac |
こいつは, master / worker を1引数目に受け取ると, Spark のそれぞれのメインクラスを,それ以外の場合コマンドだと思ってそれを実行する.こいつを,コピーして,エントリーポイントとして設定する:
COPY scripts/entrypoint.bash /sbin/entrypoint.bash RUN chmod 755 /sbin/entrypoint.bash USER spark WORKDIR $SPARK_HOME ENTRYPOINT [ "/sbin/entrypoint.bash" ] CMD ["master"]
Docker Compose の設定
後は master / worker それぞれを一つずつインスタンスとして起動して,協調動作させるための設定を, Docker Compose で書く. master は以下のようにする:
master:
build: .
command: ["master"]
hostname: master
environment:
MASTER: spark://master:7077
ports:
- 4040:4040
- 6066:6066
- 7077:7077
- 8080:8080
それぞれのポートは,
- 4040: アプリケーション確認用 Web UI
- 8080: ジョブヒストリー確認用 Web UI
- 6066: Rest API
- 7077: ジョブサブミット用
という感じっぽい.なお,設定できる環境変数は,コンテナを起動した後,以下で確認できる:
docker-compose exec master cat conf/spark-env.sh.template
なお, MASTER は spark-shell などの CLI 用に設定している. CLI はこの変数を見て master のジョブサブミット先を決めるっぽい. worker の方は以下のように書く:
worker1:
build: .
command: ["worker", "spark://master:7077"]
depends_on:
- master
environment:
SPARK_WORKER_WEBUI_PORT: 8081
ports:
- 8081:8081
最終的にできたやつは, https://github.com/mizunashi-mana/docker-toy-spark に上げてある.
spark-shell を動かす
後は spark-shell を spark://localhost:7077 に設定して起動すればいい:
spark-shell --master spark://localhost:7077
master のコンテナでも起動できて,次のようにする:
docker-compose exec master spark-shell
spark-shell は SparkContext が sc に束縛されて,諸々がデフォルトで import されてる sbt みたいな感じっぽい.例えば次のような入力ができる:
scala> sc.parallelize(0 until 100).flatMap { p => (0 until 100).map { i => ((p + i) % 40, i) } }.groupByKey().count()
res1: Long = 40
論理プランは次のメソッドで見れる:
scala> sc.parallelize(0 until 100).flatMap { p => (0 until 100).map { i => ((p + i) % 40, i) } }.groupByKey().toDebugString
res3: String =
(2) ShuffledRDD[11] at groupByKey at <console>:25 []
+-(2) MapPartitionsRDD[10] at flatMap at <console>:25 []
| ParallelCollectionRDD[9] at parallelize at <console>:25 []
最初の (N) の N はパーティション数, [N] の N は RDD の ID っぽい.例えば, parallelize と groupByKey でパーティション数を指定してみる:
scala> sc.parallelize(0 until 100, 100).flatMap { p => (0 until 100).map { i => ((p + i) % 40, i) } }.groupByKey(50).toDebugString
res5: String =
(50) ShuffledRDD[17] at groupByKey at <console>:25 []
+-(100) MapPartitionsRDD[16] at flatMap at <console>:25 []
| ParallelCollectionRDD[15] at parallelize at <console>:25 []
なお, :q で閉じれる.アクションを実行すると,ジョブが発行される.ジョブは http://localhost:4040 から見れる.画面は以下の感じ:
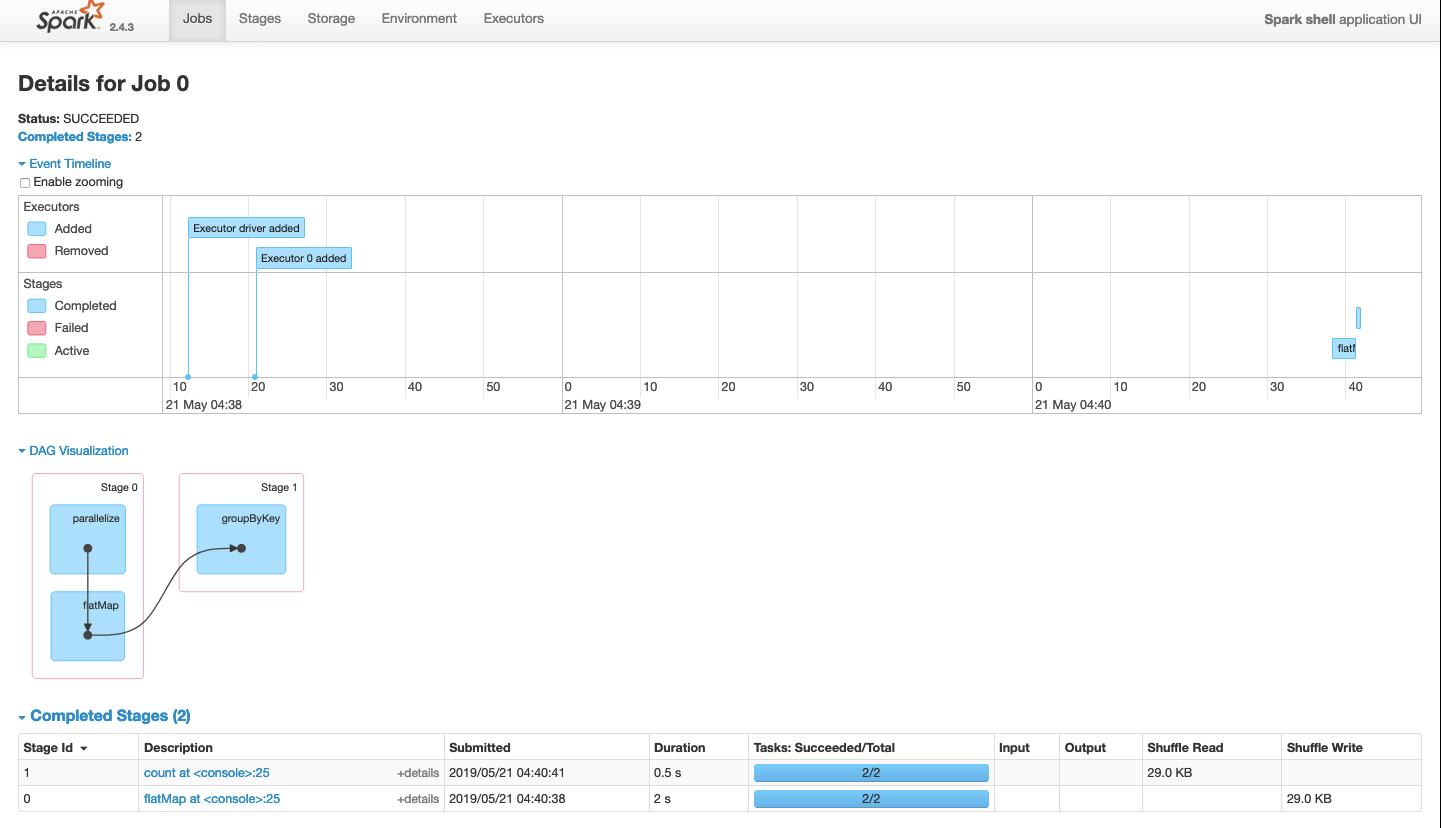
タスクの詳細は,ステージ欄にあるリンクから見れるっぽい.