Apache Spark についての覚書
2019年05月12日に投稿 (2020年03月29日に更新) • カテゴリ:フレームワーク
ちょっと興味があったので, Apache Spark 関連についていくつか調べたことメモる.なお,僕は最近まで Apache Spark は MapReduce してると思ってたぐらいだし, Hadoop も Spark も触ったことない人間なんで,完全に信憑性はないです.そこはよろしく.
分散処理の抽象
Apache Spark 周りってほぼ歴史の話なんで,まずはそこから. Google の MapReduce から色々分散処理の抽象化が提唱されてきた.それぞれが Apache Spark の元になってるやつ.他にも色々あるっぽいけど,とりあえず目についたのをまとめてみた.
MapReduce
Google が提案した技術で,最近の潮流の出所なんかな? 気持ちを知りたい時は, Google の有名な論文を読むのが正直早い気がするし,確実な気がする [1] .以下のやつ:
Jeffrey, D., & Sanjay, G. (2004). MapReduce: simplified data processing on large clusters. In 6th OSDI 2004 (pp. 137–150). Retrieved from https://www.usenix.org/legacy/events/osdi04/tech/dean.html
論文と聞くと身構える人いるかもだけど,ページ数としては 13 ページで,かなり抽象化して大事な部分だけが書かれてるので,多分読みやすいと思う.特に 4 節だけでも読むのがいいかもしれない.これは, Apache Spark の構成知る上でも役に立つ知識だと思う.
基本的な考え方は簡単で,キーバリューペアの列に対して map / reduce の 2 種類の処理で分散処理プログラミングを行うというもの.例えば,よく使われるワードカウントの例だと,擬似コードになるけど,以下の感じ:
map(key: String, value: String):
for w in value.Words():
EmitIntermediate(key: w, value: "1")
reduce(key: String, values: Iterator<String>):
let result: Int = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))
この例は最初にドキュメントのパス名と内容の文字列が大量に与えられ,それに対して単語ごとの出現回数を数え出力することを想定している.やってることは大体想像つくと思うけど,
- map 処理で各ドキュメントの文字列を単語ごとに区切り,それぞれ単語をキーとしてカウント 1 を中間出力する.
- reduce で中間出力の各カウント結果を,単語ごとに合計して出力する.
ここで,中間出力は 1 が出てくることは決まってるんだから, result += ParseInt(v) なんて書かずに result++ って書けばいいじゃんって思う人がいるかもだけど,これは Combiner 最適化というものを想定しているため.これについては,後述する.
考え方だけだとこんな感じなんだけど,この実装をどうするかという問題があり,これについて上の論文で簡潔な説明と分かりやすい図が載ってるのでそこだけ紹介しておく.
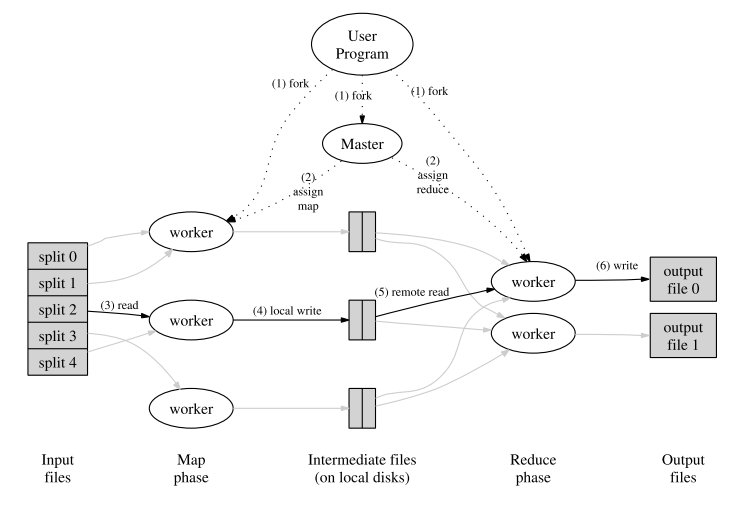
まず,上の図を見れば分かると思うけど, MapReduce には 4 人登場人物がいる.それぞれ
- ユーザプログラム
- 通常 1 つで, map / reduce 処理及び入出力ファイルのフォーマットなどが書かれている.
- マスターサーバ
- 通常 1 つで,ユーザプログラムを元にタスクを生成・管理する.
- ワーカサーバ
- たくさんあって,マスターサーバから割り当てられたタスクを忠実にこなす.
- ストレージ
- ワーカサーバ度に用意されていて,仮想的に分散ファイルシステムにより統合する形で構成されている.
となる.これらの登場人物が以下の処理を行うことで,全体の処理を完遂する:
- ユーザプログラムは,入力 (デフォルトは,改行区切りで一列がキーバリューペア一個に相当するもの) を 個に区切ってストレージに置いておく.次に,マスターサーバ,ワーカサーバが起動され,ユーザプログラムから,区切られた入力とそれをキーバリューペアにパースする方法, map / reduce の処理内容が与えられる.
- マスターサーバは, 個の map タスクを map 処理から, 個の reduce タスクを reduce 処理から生成し,処理待ち状態のワーカサーバに割り当てていく.
- map タスクが割り当てられたワーカサーバは,区切られた入力の中から自身のためのものを選び,パースして順に map 処理に投げていく.
- map タスクが割り当てられたワーカサーバは,受け取った中間結果をローカルディスクに 個に区切って置いていく.この区切り方がポイントなんだけど,それについては後で.そして処理が終わったら,結果を置いた場所をマスターサーバに通知する.
- reduce タスクが割り当てられたワーカサーバは,中間結果の場所を受け取ると,その場所をリモートアクセスで参照し,キーごとにまとめる.
- reduce タスクが割り当てられたわーかサーバは,全ての中間結果を受け取ったら,加工した中間結果を reduce 処理になげ,出てきた結果を出力ファイルに追加する.
- マスターサーバは全てのタスクが終了したら,ユーザプログラムに処理を戻す.
なお, map タスクが生成した中間結果を, reduce タスクでキーごとにまとめる処理は,一般にシャッフルと呼ばれてるっぽい.大雑把には次のステップを行う:
- パーティション
- map タスクはシャッフルの際,任意のキーに紐づくデータを 1 つの reduce タスクから参照できるように,中間結果を振り分ける必要がある.これは,例えばキーのハッシュ値の での剰余 を振り分け先としてやれば,同じキーはハッシュ値が等しいため特に調整をしなくても同じ振り分け先となる.この処理はパーティションと呼ばれている.
- ソート
- 中間結果をキーごとにまとめるために, reduce タスクはデータをソートする.こうすると,前から順に処理をしていけばキーが変わらない範囲がキーごとにまとまった範囲であることが分かる.この方法は,データが大量にありメモリに収まりきらない場合に,ソートにおいても範囲チェックにおいても対応が可能という点でこうしてるっぽい.
なお,この辺用語がいまいち分からないんだけど,資料によってシャッフルが指す範囲が変わることがあって,パーティションは含んだり含まなかったりもするので注意してほしい.
さて,クラスタベースの分散処理で一番ネックとなるのがネットワーク通信の部分だ.通信するデータを削減すれば,一般的にマシンパワーを改善するより劇的にパフォーマンスが変わる場合が多い. MapReduce では,大きなネットワーク通信を必要とするのがシャッフルを行うときだ.そこで reduce タスクに渡す前に map タスクの方で通信量を減らすための最適化手法, Combiner 最適化が知られている.これは, reduce タスクの実装パターンのよくある傾向を利用する.一般的に, reduce タスクは可換性と結合性を持つ演算で実装される場合が多い.つまり,部分的に先に計算して後からそれを総計する手法がとれる場合が多い.この部分的に先に計算する部分をユーザから追加で与えてもらい, map タスクが終わった後ワーカごとに処理する.そして,それをシャッフルにかける.この部分的に先に計算する処理が combiner と呼ばれる.先に出したワードカウントの例だと reduce の処理を combiner として設定することで, map タスクが終了したらシャッフル時にワーカ度のワード総計がまず行われ,その後その総計がパーティションされた後ソートされ,最終的にその値を元に全体の総計をとるといった流れになる. combiner 最適化はあくまで最適化なので,その適用方法は実装によって異なるし,もちろん combiner をかけることにより情報が欠落すると問題が起きる処理には適用できないので,この最適化が適用できるかはユーザ判断ということになる.ただ性能が劇的に改善する場合が多いので,割と一般的に使われてるようだ.
Pregel
これもまた, Google が出所の技術で,やっぱり論文が出てるのでそれを読むのが良さそう:
Malewicz, G., Austern, M. H., Bik, A. J. ., Dehnert, J. C., Horn, I., Leiser, N., & Czajkowski, G. (2010). Pregel: A System for Large-Scale Graph Processing. In Proceedings of the 2010 international conference on Management of data - SIGMOD ’10 (p. 135). New York, New York, USA: ACM Press. https://doi.org/10.1145/1807167.1807184
こっちも 11 ページぐらいなので,読んでみるのがいいと思うけど, MapReduce のよりちょっと読みにくいかも.
Pregel はグラフ処理の分散プログラミングに特化した抽象で,グラフが与えられた時にそれを分散処理してグラフを出力するプログラミングを支援する.考え方的には,グラフの頂点単位で処理を行わせ,メッセージ送受信で協調させることで,分散化を図るというもの.まずはどのようにプログラムを書くのかの例を見てもらった方が分かりやすいと思うので,擬似コードを挙げてみる.例えば,頂点に数値が割り当てられてる場合の,単一始点最短経路問題を解くプログラムは以下の感じになる:
const sourceId: VertexId = 0
compute(v: Vertex, msgs: Iterator<Message>):
let mindist: Int =
if v.Id() == sourceId then 0 else MaxInt()
for msg in msgs:
mindist = Min(mindist, msg.Value())
if mindist < v.Value():
for e in v.OutEdges():
SendMessageTo(
targetId: edge.TargetVertexId(),
value: mindist + e.Value(),
)
VoteToHalt()
このプログラムは,最終的に頂点番号 0 からの最短距離を各頂点が値として持つようなグラフを出力する.Pregel での処理内容は,大雑把には,
- 全ての頂点の状態を Active にする.
- 状態が Active な各頂点毎に compute を実行する.
- 全ての compute を実行しメッセージの送信を終えたら,全ての頂点の状態を更新する.
- 2 に戻る.
を繰り返す.ここで特徴として,頂点は Active / InActive の 2 種類の状態を持ち,全ての頂点が InActive になれば自動的に処理が終わるようになっている.で,頂点状態の更新で状態は切り替わる.この切り替えの仕方は以下の手順で行われる.
- VoteToHalt が compute で呼ばれていた場合, InActive になる.
- メッセージを受信した場合, Active になる.
なお, 2 は例え VoteToHalt が呼ばれたとしても,元々頂点が InActive で compute を実行していなくても,強制的に発動することに注意してほしい.で,分散処理なので MapReduce の時と同じくマスターとワーカがあり,マスターはグラフの頂点毎にタスクをワーカに発行するのが, Pregel モデルになる.
Pregel モデルの特徴は,同期にある.つまり,単純に頂点毎にタスクを発行してそれぞれ好き勝手に進めさせるのではなく, compute を実行する度に同期して一斉に頂点の状態更新を行いまたもう一度 compute を実行するという流れだ.これは元々バルク同期並列に着想を得たものらしく, Pregel モデルでもこの同期をバルク同期並列と呼んでいる.また,同期を挟むまでの一回の計算単位を 1 スーパーステップという単位で呼んでいる.メッセージの受信は同期を挟んだタイミングで行われ,あるスーパーステップではその前のスーパーステップで送信されたメッセージしか取り扱えない.このようなモデルにより,グラフ分散処理を実装に合わせながら,それなりに書きやすい抽象で提供している.
なお, SendMessageTo は送り先の頂点番号が分かれば実際にはどの頂点にもメッセージを送れるのだが,送付先として情報が分かるのが隣接頂点ぐらいなので,自然処理は限られてくる.ただ,実際には全頂点で値を共有したいということがよくある.そこで,集約器 (aggregator) という仕組みも用意されていて,各頂点から値を受け取ってその値を演算して一つの値にし,その値を次のスーパーステップで参照できるようになっている.
また, Pregel モデルでも Combiner 最適化が有効で,メッセージをワーカ度に先にまとめてしまって,その後頂点でまとめたものをさらに処理することが問題なくできる場合に, combiner を追加することで性能を改善できる.最短経路の例だと以下の感じ:
const sourceId: VertexId = 0
compute(v: Vertex, msgs: Iterator<Message>):
let mindist: Int =
if v.Id() == sourceId then 0 else MaxInt()
for msg in msgs:
mindist = Min(mindist, msg.Value())
if mindist < v.Value():
for e in v.OutEdges():
SendMessageTo(
targetId: edge.TargetVertexId(),
value: mindist + e.Value(),
)
VoteToHalt()
#[combiner]
combine(msgs: Iterator<Message>, v: Vertex):
let mindist: Int = MaxInt()
for msg in msgs:
mindist = Min(mindist, msg.Value())
Emit(mindist)
これにより,メッセージはワーカの中で最小のものだけが送られるようになり,さらにそれぞれのワーカから送られたきたものの中から最小のものが compute で計算される.
なお, Pregel モデルは MapReduce に落とし込むことができ,単純に compute を map に,同期を reduce にすれば良い.一応,論文には実装のアウトラインも載っているが,そこまで目新しいことはないと思うので,こちらは割愛する.興味があれば読んでみてくれという感じ.
分散ストリーム処理
分散ストリーム処理は,リアルタイムかつ継続性のある分散処理に特化した抽象.なんか一応出したけど,あんまり調べてない.とりあえず,文献だけ.
Google の実装である MillWheel の紹介
Akidau, T., Whittle, S., Balikov, A., Bekiroğlu, K., Chernyak, S., Haberman, J., … Nordstrom, P. (2013). MillWheel: fault-tolerant stream processing at internet scale. Proceedings of the VLDB Endowment, 6(11), 1033–1044. https://doi.org/10.14778/2536222.2536229
Spark Streaming の仕組みの紹介
Zaharia, M., Das, T., Li, H., Hunter, T., Shenker, S., & Stoica, I. (2013). Discretized streams: fault-tolerant streaming computation at scale. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles - SOSP ’13 (pp. 423–438). New York, New York, USA: ACM Press. https://doi.org/10.1145/2517349.2522737
Spark の Structured Streaming の仕組みの紹介
Armbrust, M., Das, T., Torres, J., Yavuz, B., Zhu, S., Xin, R., … Zaharia, M. (2018). Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. In Proceedings of the 2018 International Conference on Management of Data - SIGMOD ’18 (pp. 601–613). New York, New York, USA: ACM Press. https://doi.org/10.1145/3183713.3190664
処理系を実装する際には,時間の整合性とか色々考えることがありそうだけど,実装された処理系を使う分には, MapReduce を使うにしろ他の抽象を使うにしろ,それほど大きくプログラミングスタイルは変わらないものが多いのかな.この辺は,触ってみないとなんとも言えなそう.
Apache Spark について
さて,それぞれの抽象にはそれにあった実装が,古今東西色々存在している. MapReduce の代表的なオープンソース実装としては Apache Hadoop MapReduce が有名だし, Pregel 実装としては Apache Giraph が有名だ.分散ストリーム処理は, Apache Storm があるのかな.まあ大半は Hadoop MapReduce 上の実装だったりするんだけど,それは置いておいて,元々 MapReduce はそれ自体がかなり用途を制限していて分散処理基盤としてもっと汎用的なものが欲しいという需要があったようだ.それを解決するため新たに MapReduce の代替として生み出されたのが, Apache Spark らしい.ただ,半分宣伝のためにメリットしか言ってないみたいなところもあって,実際にはかなり良し悪しがあるみたいだけど.
とりあえず,以下の文献にお世話になりながら,調べたことを書いておく.
- https://spark.apache.org/docs/latest/rdd-programming-guide.html
- https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
- https://github.com/JerryLead/SparkInternals
- https://www.slideshare.net/AGrishchenko/apache-spark-architecture
Apache Spark の構成
基本的に, Apache Spark は Hadoop 全体を塗り替えるものではなく, Hadoop のエコシステムのうち,分散処理エンジンの部分 Hadoop MapReduce の代替を目指すものっぽい.なので, Apache Spark は Hadoop のように分散ファイルシステムを持っていなくて,その代わり HDFS (Hadoop の分散ファイルシステム) が利用できるようになっている.また,クラスタマネージャは持ってるので自前で動かすこともできるが, Hadoop の YARN や Apache Mesos などでの管理にも対応してるっぽい.
ここら辺はちょっと使ったことがないので分からないが,一応 公式のデプロイガイド に書いてあるのを読む限りはそうっぽい.
Spark はそのまま生で使える DSL の他に,以下のライブラリを提供してる:
- Spark SQL
SQL クエリで Spark を操作するための機構を提供する.
https://spark.apache.org/docs/latest/sql-programming-guide.html
- Structured Streaming
Spark SQL 上で分散ストリーム処理をするための機構を提供する.
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- MLlib
分散処理上での機械学習に特化した API を提供する.
- GraphX
Pregel に対応したグラフ分散処理の機構を提供する.
https://spark.apache.org/docs/latest/graphx-programming-guide.html
- Spark Streaming
分散ストリーム処理をするための機構を提供する.
https://spark.apache.org/docs/latest/streaming-programming-guide.html
Apache Spark のアーキテクチャ
Apache Spark は,内部はかなり複雑になっていて, MapReduce とか Pregel ほど単純ではない.ただ,プログラム自体はかなり自然に書けて,以下のようになる:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | package example.spark import java.util.Random import org.apache.spark._ object SparkSample { def main(args: Array[String]) { val numMappers = 100 val numReducers = 50 val numPairs = 1000 val numSize = 1000 val sparkConf = new SparkConf().setAppName("Spark Example") val sc = new SparkContext(sparkConf) val pairs = sc .parallelize(0 until numMappers, numMappers) .flatMap { p => val ranGen = new Random val arr = new Array[(Int, Array[Byte])](numPairs) for (i <- 0 until numPairs) { val byteArr = new Array[Byte](numSize) ranGen.nextBytes(byteArr) arr(i) = (ranGen.nextInt(Int.MaxValue), byteArr) } arr } .cache() // Enforce the calculation for cache pairs.count() println(pairs.groupByKey(numReducers).countByKey()) sc.stop() } } |
Scala で書く場合,ほぼコレクション API と使い勝手が同じ感じになる. MapReduce ではそれぞれのタスクが自明にメソッド 1 つに対応してたけど, Spark の場合見ての通りメソッドチェーンで書かれていて,そこまで自明ではない.では,これがどのようにタスクに変換されるかだけど,大体以下の手順を通るらしい:
- メソッドチェーンから論理プラン (データ依存グラフ) が作成される.
- 論理プランから物理プラン (有向非巡回グラフ) が作成される.
- 物理プランを元にタスクを生成し,ワーカに割り当て実行する.
上のコードを例に,それぞれのやってることを大雑把に書いておく.
まずは Spark のプログラミングの基本から. Spark の処理メソッドは, RDD (Resilient Distributed Dataset) と呼ばれるオブジェクトを返してくる.上の例だと
- parallelize
- flatMap
- groupByKey
がそれぞれ RDD オブジェクトを返す.見ての通り, RDD オブジェクトは連鎖させることができ,入力から RDD を生成するメソッドと RDD オブジェクトを元に RDD オブジェクトを生成するものが存在する. RDD を連鎖によって生成した場合,その連鎖はオブジェクトに記録されている.ただ,注意して欲しいのは,メソッド 1 つに RDD 一つが必ずしも紐づくとは限らず, groupByKey は 2 つの RDD を連鎖させる.これについては,後述する.なお, Spark ではこのような RDD オブジェクトを生成するメソッドは全て遅延され,特にタスクが生成されることはないしファイルが読み込まれたりすることもない.このようなメソッドは,変換 (transformation) と呼ばれてるらしい.
逆に, RDD 以外の結果だったり Unit だったりを返してくるメソッドも存在する.上の例だと
- count
- countByKey
がそう.こいつらが呼ばれると初めてタスクの振り分け・実行が行われる.この辺は O/R マッパーとかと同じ.これをアクション (action) と呼ぶ.
生成される RDD は変換ごとに異なる.変換の処理内容によってもそうなのだが,主に元となった RDD の結果がどう生成した RDD に依存しているかが,論理プランを決めるとき重要になる.さて, Spark では MapReduce と同じように入出力データはいくつかの区分に区切られている.これをパーティション (partition) と呼ぶ.それぞれの RDD では異なるパーティション構成が用いられる. RDD のデータ依存関係とは出力する RDD (親 RDD) のパーティションとそれを受け取る RDD (子 RDD) のパーティションがどのように依存しあってるかを表す関係である.論理プランは,このパーティションを頂点としてデータ依存関係を辺とするデータ依存グラフになる.なお今回出していないが,親 RDD は 1 つの子 RDD に対し複数ある場合もあって, join / union などのオペレータはそういう子 RDD を作る.
Spark のデータ依存関係は大きく 2 種類ある [2] :
- 限定依存 (narrow dependency)
- 親 RDD のパーティションは全て,高々 1 つの子 RDD のパーティションに依存する.
- 広域依存 (shuffle dependency / wide dependency)
- 親 RDD のパーティションに対し,子 RDD の複数のパーティションが紐づく場合がある.
この依存関係の違いは,シャッフルが必要あるかないかで,限定依存はシャッフルが必要ないため依存関係がネットワーク越しにならないようタスクを振り分ければ速く処理できるが,広域依存はシャッフルが必要になる.
- map は入力と出力が 1 対 1 対応してるので限定依存
- groupByKey は一般にどのキーがどのパーティションに含まれるか,実行前に判別することは難しいので,広域依存扱い
という感じになる.上のプログラムだと以下の論理プランが生成されるっぽい:
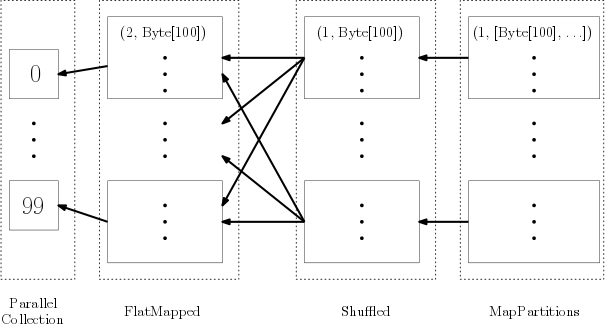
点線は RDD を,実線はパーティションを表している.それぞれの RDD は
- ParallelCollection
- parallelize に対応し,指定された数だけパーティションを作る.
- FlatMapped
- flatMap に対応し,親 RDD のパーティションの数だけパーティションを作る.
- Shuffled
- groupByKey の前処理に対応し,シャッフルして指定された数だけパーティションを作り,同じキーを持つ要素をかき集める.
- MapPartitions
- groupByKey の後処理に対応し,この RDD 自体はパーティションごとに変換を行う.今回は同じキーを持つ要素を一つの要素にまとめる.
みたいな感じになる.
論理プランは以上の感じでデータ依存グラフを作る.この論理プランを元に,実際の実行フローに合わせたグラフ,物理プランが作られる.物理プランは以下の手順で作られる,タスクを頂点として,変換を辺としたグラフになる:
まず,論理プランを部分グラフに分けるらしい.この部分グラフをステージと呼ぶ.
なお,ステージの分け方としては大雑把に言えば,出力から逆向きに辿り広域依存を区切りに分けるらしい.
ステージそれぞれで最後の RDD のパーティションごとにタスクを生成する.
ステージがアクション結果を生成するなら result タスク,それ以外の場合 shuffle-map タスクを割り当てる.shuffle-map タスクは生成結果にシャッフルを必要とする.
上のプログラムだと以下の物理プランが生成されるっぽい:
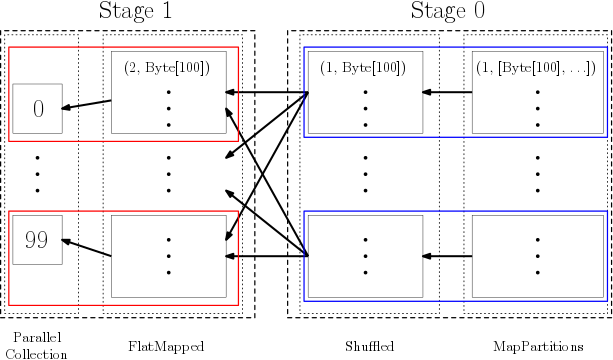
赤線が shuffle-map タスク,青線が result タスクになる.ステージもタスクも,出力側から見て区切っていくけど,グラフ自体は入力側から辺が張られるのかな? この辺ちょっと分からなかったので,辺は書かなかった.まあ,こんな感じのが出来上がるっぽい.
後は,入力側のステージのタスクから,各ステージごとに順に実行していくみたい.そろそろ疲れたきたので,今日はこの辺で.
まとめ
ここらへん話聞くだけでかなり知らない領域だったので,実際に調べてみて結構色々知れたのは良かったと思う.ただ,キャッシュの仕組みとかシャッフルの仕組みにも Hadoop での経験を生かした工夫があるらしく,そこら辺ちょっと調べきれてないので,また時間があったら調べてみたい.後, Spark をすぐ起動できる Docker イメージとかあるっぽいので,近いうちに触ってみようかなと思った. Spark は spark shell とかいう対話式でプログラム実行できるやつがあるらしく,結構色々充実してそう.後, Spark SQL とか Hive とかは中で SQL を RDD や MapReduce に変換してるらしく [3] ,その辺の仕組みとかもちょっと興味があるので調べてみたい.
ま,気が向いたらその辺の記事とかも書くかもねってことで,以上.
| [1] | あんまり文献読んでない人並みの感想 |
| [2] | なお,違う定義の分け方もあるらしく,この辺の用語はちょっと怪しいかも.まあ重要なのは用語ではなく,なぜこの分け方をするかなので,今回はシャッフルが自明に必要あるかないかで分ける定義を採用した. Spark 内部で実際どの種類分けがされているかは調べた方が良さそうと思って調べてない. |
| [3] | まあ単純に SQL パースして, JOIN とか GROUP BY はシャッフルを入れたりして,対応する変換を出力するとかっぽいけど.ただそれが分かると,Spark や Hadoop 上で SQL 実行する時のパフォーマンス予想とかできそうで,役に立ちそうでもある. |